A Guide to Deep Learning and How It Works

Deep learning is attracting rapidly growing research and development in today’s world, where artificial intelligence is exponentially growing with newer breakthroughs by the day.
What is Deep Learning?
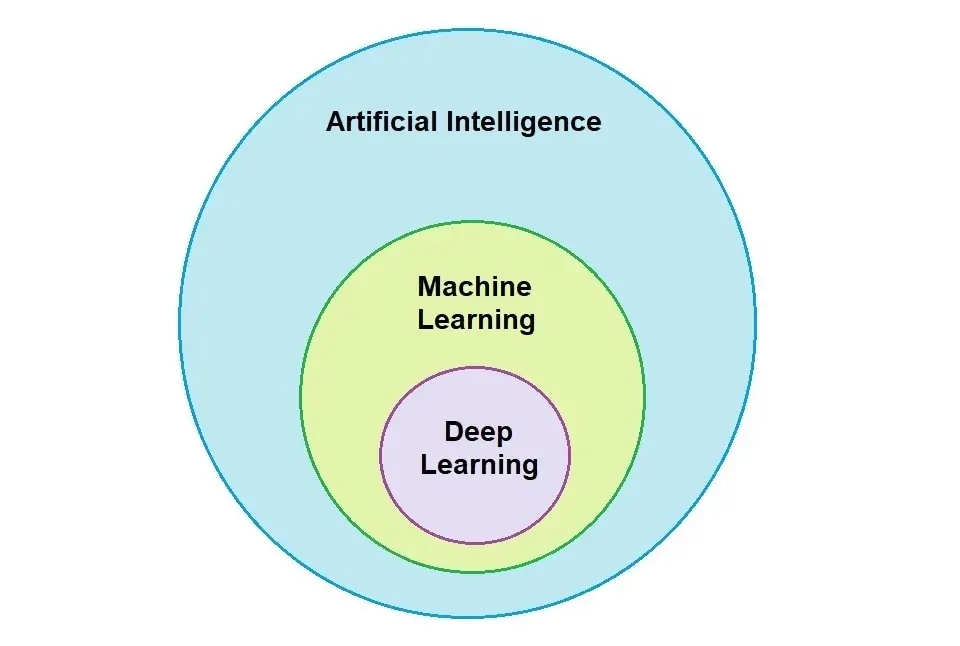
Deep Learning is one of the methodologies that is receiving a lot of attention.
Deep Learning (DL) is a subset of Machine Learning that teaches computers to do what humans naturally do. It trains an algorithm to predict outputs given a set of inputs. It uses both Supervised and Unsupervised Learning. You may like to read about different types of types of machine learning. However, for the benefit of this article, I will define what Supervised and Unsupervised learning are:
Supervised Learning is when the algorithm learns on a labeled dataset and analyses the training data. These labeled data sets have inputs and expected outputs.
Unsupervised Learning learns on unlabeled data, inferring more about hidden structures to produce accurate and reliable outputs.
The traditional computer programming method is based on input and a set of rules combined to get the desired output. However, in Machine Learning and Deep Learning, the input creates the set of rules or the output.
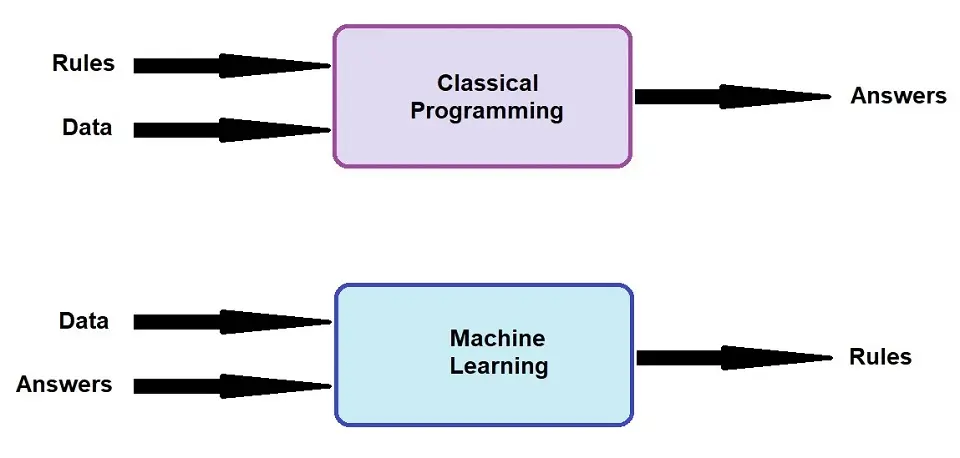
Deep Learning is getting a lot of attention because DL models have been shown to achieve higher recognition accuracy levels than ever before. In recent advances, it has exceeded human-level performance in tasks such as image recognition.
How does Deep Learning work?
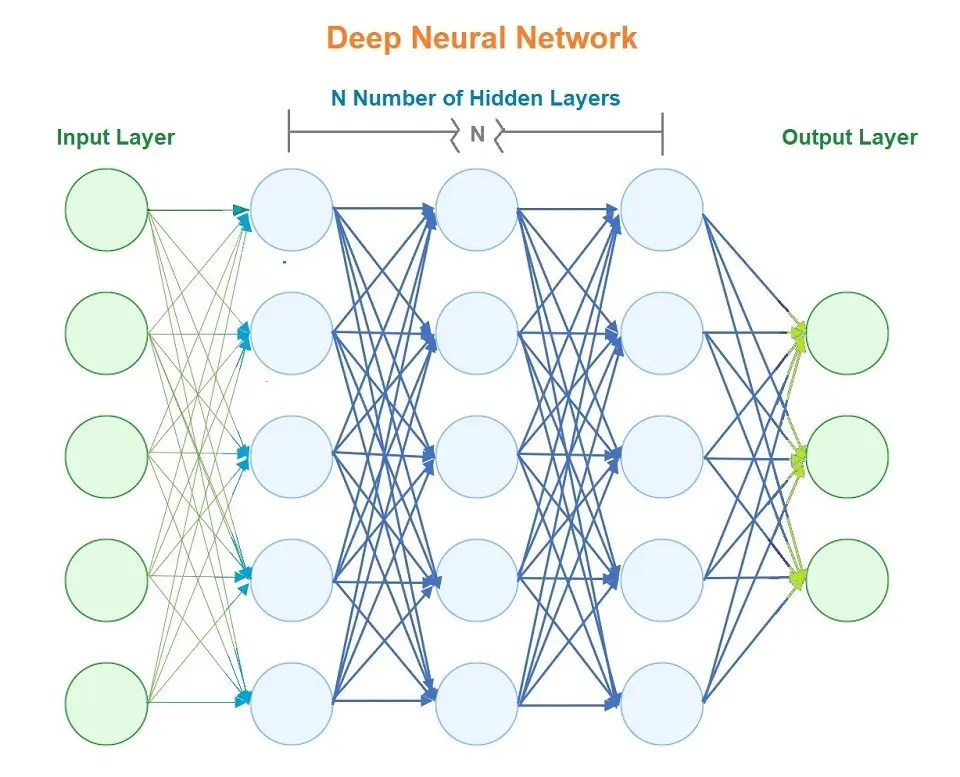
Deep learning models use artificial neural networks to extract information. You may have also heard it referred to as Deep Neural Network, where ” Deep ” refers to the number of hidden layers in the neural network.
What is an Artificial Neural Network?
Artificial Neural Networks are made up of artificial neurons or nodes in terms of AI. Artificial Intelligence is based on human intelligence; therefore, we can correlate a Neural Network with the structure of biological neurons, similar to the human brain.
ANN or Artificial Neural Networks are made up of neurons containing three layers: an input layer, one or more hidden layers, and an output layer. Each of these neurons is connected to another neuron, where computation happens.
- Input Layer – receives the input data.
- Hidden Layers – perform mathematical computations on the input data.
- Output Layer – returns the output data.
An Artificial Neural Network to be considered in Deep Learning requires more than one hidden layer.
To understand the process of Deep Neural Networks, we need to understand Weight and Bias concepts.
Weight and Bias
The concepts of Weight and Bias play an important role in the movement of an Artificial Neural Network.
Weight controls the strength of the connection between two neurons. It decides how much influence the input has on the output.
Bias will always have a value of 1 and is an additional input into the next layer. The aim of having a bias is to guarantee that there will always be activation in the neurons, even if the input is 0. The previous layer does not influence them; however, they have their own weights.
An Artificial Neural Network with two variables showing Weight and Bias:
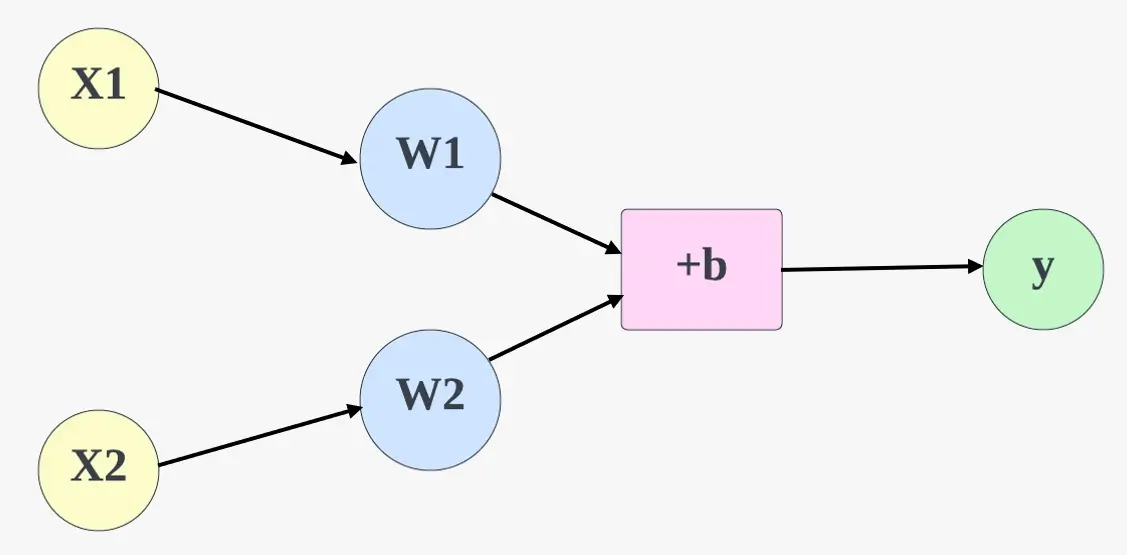
The formula to calculating y would look like this:
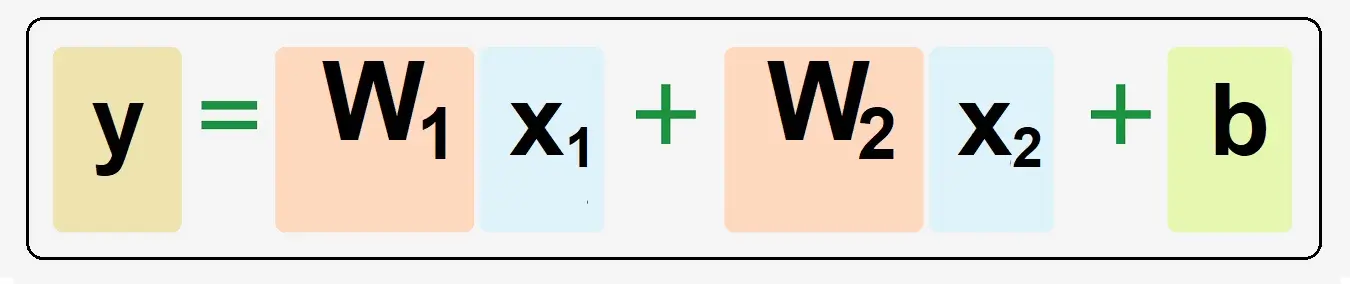
Hidden Layer
The Hidden layers are the secret sauce of your neural network. It is a layer that receives input from another layer, either the input layer or another hidden layer. It provides the output to another layer, either another hidden layer or an output layer.
We call them “hidden” because we don’t know the true values of their nodes in the training dataset. A neural network has to have at least one hidden layer to be classed as a neural network. Networks with multiple hidden layers are called deep neural networks.
Activation Function
The diagram and formula above do not include a critical part of Artificial Neural Networks, and that is Activation Functions.
In Layman’s terms, Activation Functions deliver outputs based on the input. The weighted sum of the input is transformed into output via a node or nodes.
Activation Functions help the network to learn complex patterns in the data and are at the end as it decides what is to be fired to the next neuron. The activation Function is sometimes known as the ‘Transfer Function’; as it transfers the next move.
There are different types of Activation Functions, and their choice greatly impacts the neural network’s performance. Activation Functions in the hidden layer control how well the neural network model learns on the training dataset. It defines the type of predictions the model can make; this is why it is so critical. Different Activation Functions can be used in different parts of the model to achieve better capability and performance levels.
The Process
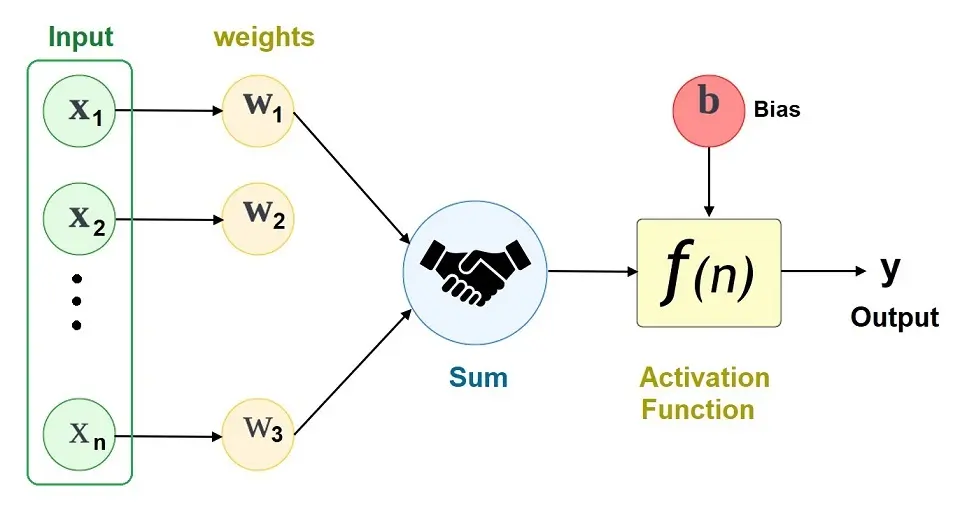
Data is received and sent through the input layer; at this point, weights are assigned to each of the variables of the data. The input variables are multiplied by their respective weights and then summed up.
Once the input variables have been multiplied by their respective weight, the Bias will be added to it. The sum of this is then passed through an activation function, which determines the output. If the output meets or exceeds a specific threshold, it activates the neuron and passes the data from one connected layer to another in the network.
The result in the next neuron now becomes the input for the next neuron. This process is known as Feedforward Network, as the information always moves in one direction (forward).
Another process is called Backpropagation, sometimes abbreviated as “backprop,” which is the messenger who tells the Neural Network whether it made a mistake when making a prediction.
Backpropagation goes through the following steps:
- The Neural Network guesses about the data.
- The Neural Network is measured with a loss function.
- The error is backpropagated to be adjusted and corrected.
When an error is caused due to the network guessing the data, Backpropagation takes the error and adjusts the neural network’s parameters in the direction of less error. This is done by Gradient Descent.
Gradient Descent
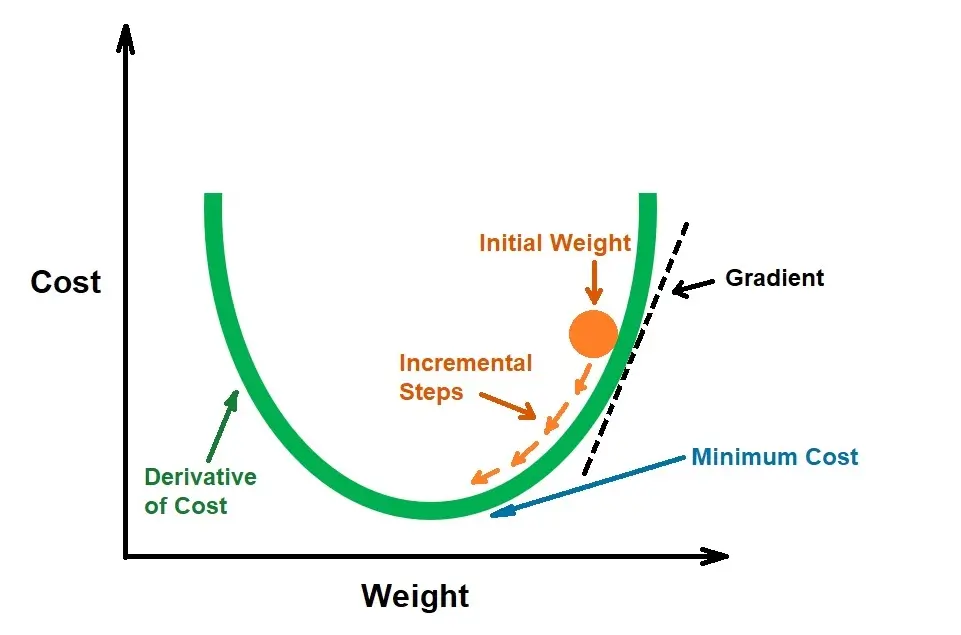
To understand Gradient Descent, we need to define Cost Function.
The Cost Function is a measure of how efficient a neural network is regarding its given training sample and the expected output. It shows us how wrong and far off the AI’s outputs were from the correct outputs. In the ideal world, we would want a Cost Function of 0, telling us that our AI’s outputs are the same as the data set outputs.
Gradient Descent is an optimization algorithm that is used to train models and neural networks to help learn and reduce the Cost Function.
A gradient is a slope, and all slopes can be expressed as having a relationship between two variables: “y over x.” In Neural Networks, ‘y’ is the error produced, and ‘x’ is the parameter of the Neural Network.
The parameters and the error have a relationship; therefore, we can either increase or decrease the error by changing the parameters.
This is done by changing the weights in small increments after each data set iteration. Then, Deep Learning automatically updates the weights, allowing us to see the lowest error in which direction.
And that is how Deep Learning works.

Nisha Arya is a Data Scientist and Technical writer from London.
Having worked in the world of Data Science, she is particularly interested in providing Data Science career advice or tutorials and theory-based knowledge around Data Science. She is a keen learner seeking to broaden her tech knowledge and writing skills while helping guide others.