A Guide to Clustering in Machine Learning
When we cluster things, we put them into groups. In Machine Learning, Clustering is the process of dividing data points into particular groups. One group will have similar data points and differentiate from those with other data points. It is purely based on the patterns, relationships, and correlations in the data.
Clustering is a form of Unsupervised Learning. Let’s quickly recap the definition of Unsupervised Learning for this article.
Unsupervised Learning is when the machine learning algorithm learns on unlabeled data. It uses its knowledge to infer more about hidden structures to produce accurate and reliable outputs. Please refer to the article “Types of Machine Learning” for unsupervised learning.
Cluster Validation in Machine Learning
Cluster Validation is a terminology used to evaluate the accuracy of the Clustering algorithm results. This technique avoids finding patterns in random data and allows you to compare two algorithms.
Cluster Validation can be split into three groups:
- Internal Cluster Validation – this purely uses internal information of a Clustering process to evaluate its performance.
- External Cluster Validation – this uses external information, such as labeled data, to compare the results and validity of a Cluster analysis. In this approach, as we already know the ‘true’ cluster labels, we can use this to help us select the right algorithms.
- Relative Cluster Validation – in this approach, we evaluate the clustering structure by tuning the different parameter values for the same algorithm.
Internal Cluster Validation approach
Using Internal Cluster Validation, we can use three approaches to achieve accurate grouping. Distance is used to measure all of these approaches.
These are:
- Compactness
- Separation
- Connectivity
Compactness
Compactness, also known as Cluster Cohesion, is when the machine learning algorithms measure how close the data points are within the same cluster. A low within-cluster variation is a good way to indicate the compactness of particular data points, proving good Clustering.
Metrics such as Euclidean distance, Manhattan distance, Minkowski distance, and Hamming distance are used.
An example of an algorithm that uses this approach is K-means Clustering.
Separation
Separation measures how well-separated a cluster is from its neighboring cluster or other clusters. To measure the separations, we use:
- The distance between the center of the clusters
- The distance between objects in different clusters
Connectivity
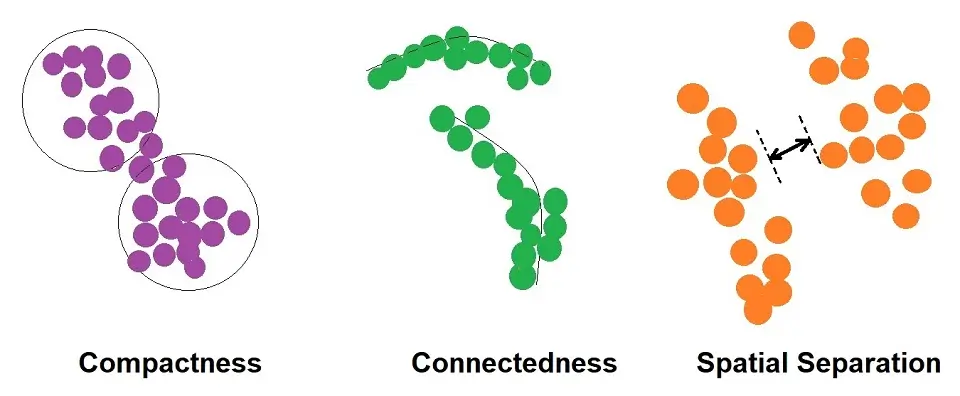
Connectivity is when the data points in a cluster are next to each other or highly connected.
Metrics such as Epsilon Distance are used in this approach. It uses a technique that calculates the average distance between each point.
An example of an algorithm that uses this approach is Spectral Clustering.
Types of Clustering
Clustering can be split into categories:
- Hard Clustering: In this case, each data point either belongs to a specific cluster entirely or does not.
- Soft Clustering: In this case, the probability is used to understand the likelihood that a data point belongs to a specific cluster rather than assigning data points to a specific cluster.
Types of Clustering Algorithm
There are four different types of Clustering algorithm approaches:
- Connectivity models
- Centroid models
- Distribution models
- Density Models
Connectivity models
Similar to the Connectivity Internal Cluster Validation approach above, Connectivity Models are based on the fact that data points in the same data place have similarities. How these models work is by using two different approaches.
- One approach is classifying the data points into different clusters and then compiling them into specific clusters as the distance decreases.
- The second approach is classifying the data points as single clusters and separating them into new clusters as the distance increases.
Although this approach is good, it doesn’t work well with big data sets as it lacks scalability. An example of this type of model is Hierarchical Clustering.
Centroid Models
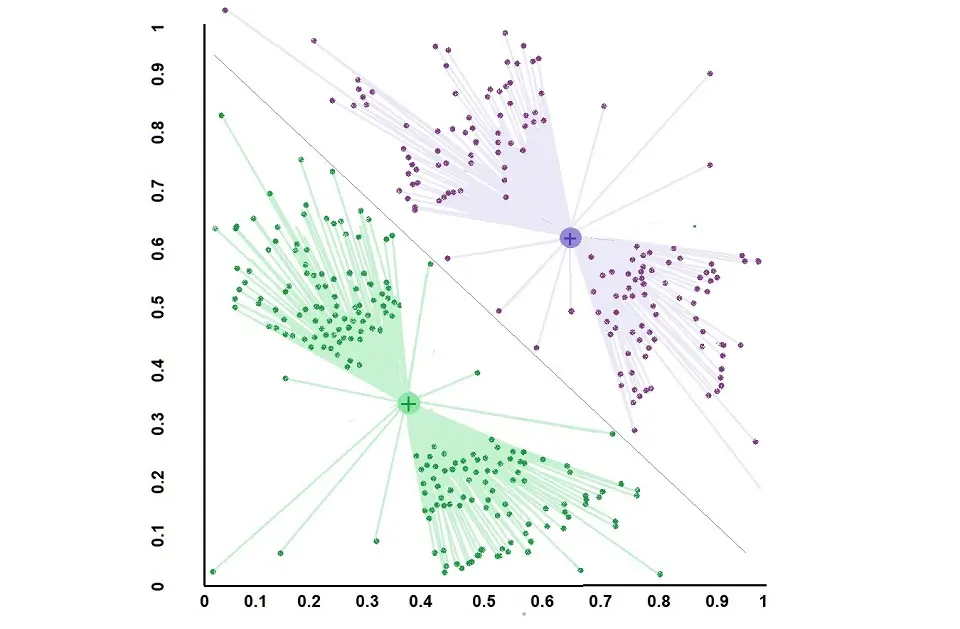
Similar to the Compactness approach in Internal Cluster Validation, Centroid Models use the notion that data points close to the center of clusters have a relation. As a result, centroid Model algorithms are efficient. However, they are sensitive to outliers.
This is an iterative process for the model to find its desired optimum for each data point.
An example of this type of model is K-means Clustering.
Distribution Models
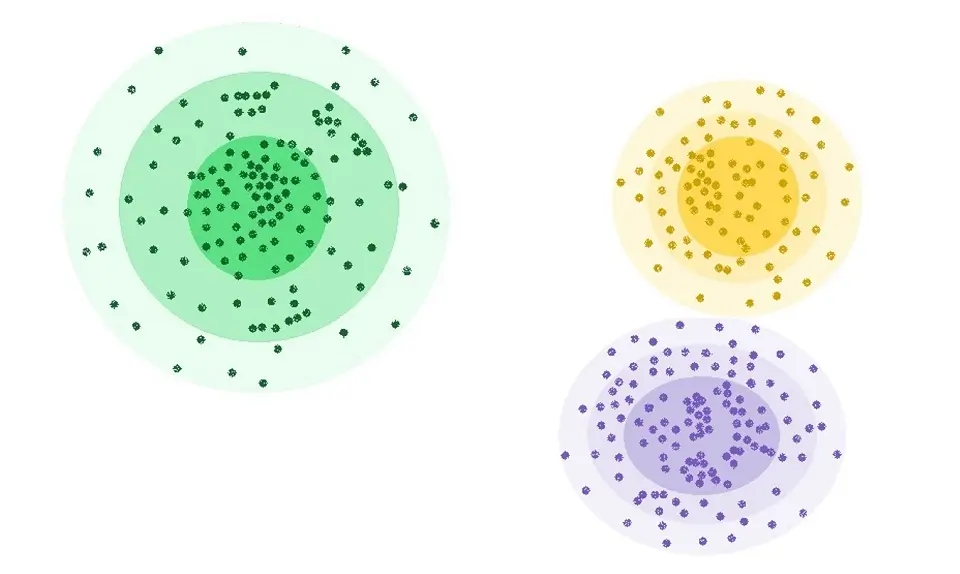
The distribution model algorithm is based on how probable it is that all the data points in a particular cluster belong to that specific distribution. For example, Gaussian Distribution, also known as Normal Distribution, is typically used here.
As the distance from the distribution (cluster) center increases, the probability that a data point belongs to that distribution decreases. As a result, these models typically suffer from overfitting.
An example of this type of model is the Expectation-Maximization algorithm.
Density Models
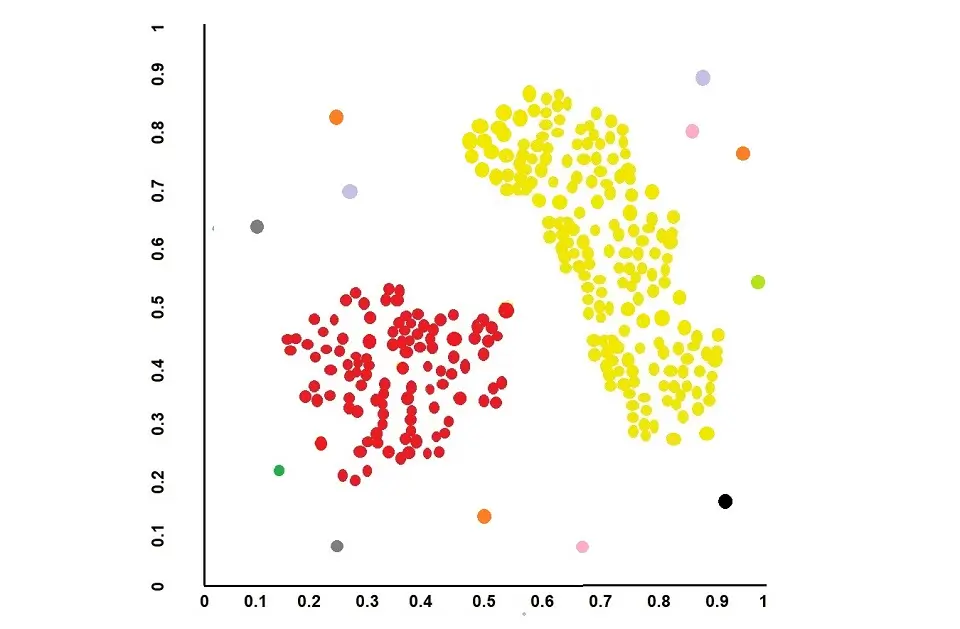
Density Models use the approach of connecting areas of high density into clusters. The model will search the data space for high-density data points, isolate these regions, and collate them into the same cluster.
An example of this type of model is Density-based spatial Clustering of applications with noise (DBSCAN)
Clustering Application
Here is a comprehensive list of applications across various domains:
Marketing and Sales
- Customer Segmentation: Grouping customers based on purchasing behavior, demographics, or responses to marketing campaigns.
- Targeted Marketing: Identifying groups with specific traits to tailor marketing strategies.
- Market Basket Analysis: Understanding product purchase patterns and associations.
Finance
- Fraud Detection: Clustering to identify unusual patterns that signify fraudulent activity.
- Credit Scoring: Grouping customers into different risk categories.
- Portfolio Management: Grouping stocks to design diversified investment portfolios.
Biology and Medicine
- Genetic Clustering: Discovering the existence of various genetic clusters in the human population or other species.
- Protein Function Prediction: Grouping proteins with similar functions to predict the function of newly discovered proteins.
- Patient Grouping: Segmenting patients based on symptoms or similar diseases for treatment analysis.
Social Networking
- Community Detection: Identifying groups or communities within social networks based on interaction patterns.
- Social Media Analysis: Segmenting topics or users into clusters to understand behavior or trends.
Image and Video Analysis
- Image Segmentation: Partitioning an image into multiple segments based on pixel similarity.
- Video Summarization: Clustering video frames to identify important segments for summarization.
Search and Information Retrieval
- Document Clustering: Organizing similar documents for efficient information retrieval.
- Web Search Result Grouping: Grouping similar results to improve search relevance.
Natural Language Processing
- Text Summarization: Grouping similar sentences to extract a summary of documents.
- Topic Modeling: Discovering the main themes in a collection of documents.
Engineering and Infrastructure
- Anomaly Detection in Network Traffic: Identifying unusual network usage patterns that could indicate a problem.
- Sensor Data Analysis: Clustering data from sensors to identify patterns or anomalies.
Retail
- Store Layout Optimization: Grouping similar items in a store for a better customer experience.
- Inventory Management: Classifying products based on sales to optimize stock levels.
Cybersecurity
- Malware Classification: Identifying types of malware based on behavior or code structure.
- Threat Detection: Grouping network events to identify potential security threats.
Transportation and Urban Planning
- Traffic Pattern Analysis: Grouping areas based on traffic patterns for urban planning.
- Ride-sharing Potential: Identifying hotspots for efficient deployment of ride-sharing vehicles.
Environmental Science
- Climate Data Analysis: Grouping similar climate patterns to understand weather dynamics.
- Species Distribution Modeling: Grouping similar habitats to predict species distribution.
Astronomy
- Star and Galaxy Clustering: Grouping celestial objects to study the structure of the cosmos.
- Astronomical Data Analysis: Classifying objects in space based on their spectral properties.
Recommender Systems
- User Profiling: Grouping users with similar preferences or behaviors.
- Product Recommendations: Recommending products based on clustered user-item interactions.
Manufacturing
- Quality Control: Clustering items based on quality metrics to identify defects.
- Process Optimization: Grouping similar process characteristics to improve efficiency.
Sports Analytics
- Performance Analysis: Clustering athletes or teams based on performance statistics.
- Talent Scouting: Identifying clusters of players with similar skills or potential.
Energy Sector
- Load Forecasting: Clustering historical power consumption data to predict future demands.
- Smart Grid Management: Grouping consumers based on consumption patterns for efficient energy distribution.
These applications represent a snapshot of the vast potential of clustering for machine learning in various fields. As data grows in complexity and volume, the role of clustering in extracting meaningful patterns and insights is becoming increasingly important.

Nisha Arya is a Data Scientist and Technical writer from London.
Having worked in the world of Data Science, she is particularly interested in providing Data Science career advice or tutorials and theory-based knowledge around Data Science. She is a keen learner seeking to broaden her tech knowledge and writing skills while helping guide others.